









X4L - wzmacniacz z DSP z serii X
Biznes „nagłośnieniowy” – w porównaniu z innymi dziedzinami techniki (np. przemysłem samochodowym, czy ...

Choć w tytule artykułu znalazło się słowo „transmisja”, nie oznacza to, że przekwalifikowaliśmy się z naszym czasopismem z „akustyki” na „telekomunikację”.
W artykule niniejszym przedstawimy bowiem kilka podstawowych, a jednocześnie fundamentalnych zasad i teorii, które są kluczowe do właściwego zaprojektowania systemów transmisji mowy – w rozumieniu nagłaśniania tejże.
Te same jednakże zasady będą też obowiązywać w nagłaśnianiu muzyki. Tak więc znajdą tu też dla siebie sporo ciekawych (mam nadzieję) informacji ci, którzy na co dzień zajmują się realizacją dźwięku „live”.
Na początek
Zapewne nieraz zdarzyło Wam się w jakimś miejscu użyteczności publicznej słyszeć nadawany komunikat, którego zrozumiałość była mocno problematyczna. Pół biedy, kiedy sytuacja taka ma miejsce na lokalnym dworcu autobusowym w „Pipidowie Górnym”, wyposażonym w tzw. kołchoźniki (lub szczekaczki) pamiętające jeszcze rządy towarzysza Edwarda G. (albo, co gorsza, również towarzysza G., ale Władysława). Jednak w przysłowiowej kieszeni otwiera się równie przysłowiowy nóż, gdy niezrozumiały bełkot wydobywa się z głośników zainstalowanych w świeżo wyremontowanym dworcu głównym wojewódzkiego miasta albo, co gorsza, w dopiero co oddanym do użytku terminalu portu lotniczego. Dlaczego tak się dzieje? Czy tak musi być?
Panuje bowiem dość powszechne przekonanie, że systemy rozgłoszeniowe „z definicji” nie brzmią dobrze i daleko im pod względem jakości do koncertowych systemów nagłośnieniowych. Jest w tym trochę racji, gdyż nie można porównywać sufitowych głośników o średnicy 5” z trójdrożnym zestawem nagłośnieniowym z wooferem 15-calowym, podpartym subbasem na dwóch osiemnastkach. Ale też zadaniem systemów rozgłoszeniowych nie jest nagłaśnianie koncertów gwiazd muzyki pop-rockowej czy orkiestr symfonicznych, ale przede wszystkim wierne i czytelne przekazywanie komunikatów, zaś w drugim rzędzie odtwarzanie sączącej się w tle muzyki. Do tego celu nie potrzebujemy przetworników z idealnie wyrównanym pasmem w zakresie od 40 Hz do 20 kHz, i to do tego jeszcze o mocy minimum 5.000 W.
Wróćmy jednak do naszego problemu – dlaczego systemy rozgłoszeniowe często brzmią tak kiepsko, że nie tylko sącząca się z nich muzyka jest masakrycznie „zmordowana”, ale nawet zrozumiałość emitowanych komunikatów pozostawia wiele do życzenia? Pomijając problem wymowy mówiących/czytających komunikaty, na co potencjalny projektant takiego systemu nie ma w zasadzie żadnego wpływu, problemem może być zły dobór komponentów systemu (np. kiepskiej jakości głośniki, słabe wzmacniacze itp.), nieprawidłowe ich rozmieszczenie lub błędy w dystrybucji sygnału. Pierwsze dwa to temat rzeka, i w tym artykule potraktujemy je tylko symbolicznie.
Odnośnie problemu pierwszego – w ostatnich latach rynek systemów instalacyjnych rozrósł się niesamowicie, gdyż producenci, całkiem zresztą słusznie, wyczuli, że na tym dopiero da się zrobić „biznes”, nie „ubliżając” nic rynkowi systemów koncertowych. Pociągnęło to za sobą podjęcie prac nad takim zaprojektowaniem głośników, wzmacniaczy, mikserów i innych urządzeń, aby jak najlepiej odpowiadały one wymogom stawianym urządzeniom pracującym w specyficznych warunkach, jakimi są np. dworce kolejowe, porty lotnicze, linie metra i inne miejsca użyteczności publicznej. Obecnie jest więc na rynku gros urządzeń naprawdę wysokiej jakości, często w całkiem przystępnych cenach, aby w miarę „kumaty” i rozeznany w rynku projektant mógł wybrać odpowiedni, dobrze grający sprzęt, adekwatny do posiadanego budżetu. My, na łamach LSI, w miarę naszych możliwości staramy się Wam w tym pomóc, prezentując w naszych artykułach urządzenia godne polecenia.
Drugi problem to już inna para kaloszy – aby umiejętnie rozplanować rozmieszczenie źródeł dźwięku nie wystarczy „ucho” i jakaś tam podstawowa wiedza z zakresu akustyki i fizyki. Problemu tego nie rozwiążą też dwa czy trzy artykuły na ten temat – to miesiące, a nawet lata pracy z obeznanymi w tym temacie ludźmi, dysponującymi odpowiednim sprzętem i oprogramowaniem do modelowania akustyki pomieszczeń czy przestrzeni. Dopiero mocne podstawy teoretyczne, poparte taką praktyką poskutkują umiejętnością zaprojektowania dobrych systemów w każdych warunkach.
Nas jednak w tym artykule interesować będzie trzeci aspekt poruszonego wcześniej problemu. Znamy bowiem przysłowie, iż każdy łańcuch jest tak mocny, jak mocne jest jego najsłabsze ogniwo. Można bowiem zaprojektować system składający się z topowych, najwyższej jakości składników (pamiętając również o, często traktowanym po macoszemu, dobrej jakości okablowaniu i wtykach). Można też idealnie dopasować rozmieszczenie źródeł dźwięku do geometrii i akustyki nagłaśnianej przestrzeni, ale pomimo tego system w dalszym ciągu będzie niedomagał. Gdzie w takim razie może leżeć przyczyna? W niewłaściwej lub niestarannie zaprojektowanej lub zrealizowanej dystrybucji sygnału.
Tak więc po tym dość przydługawym wstępie przejdźmy wreszcie do meritum, a na początek weźmy „na tapetę” tematy dotyczące
Aby umiejętnie przetwarzać sygnały, trzeba dobrze zrozumieć ich naturę. W tym przypadku naszymi sygnałami są mowa i/lub muzyka, a przetwarzanie polega na ich odpowiedniej reprodukcji za pomocą urządzeń nagłaśniających.
Aby poznać naturę tych sygnałów, musimy przyjrzeć się jak kształtuje się ich udział w paśmie częstotliwości słyszanych przez człowieka, jak wygląda dynamika tych sygnałów oraz z jakimi ich poziomami mamy do czynienia w życiu codziennym.
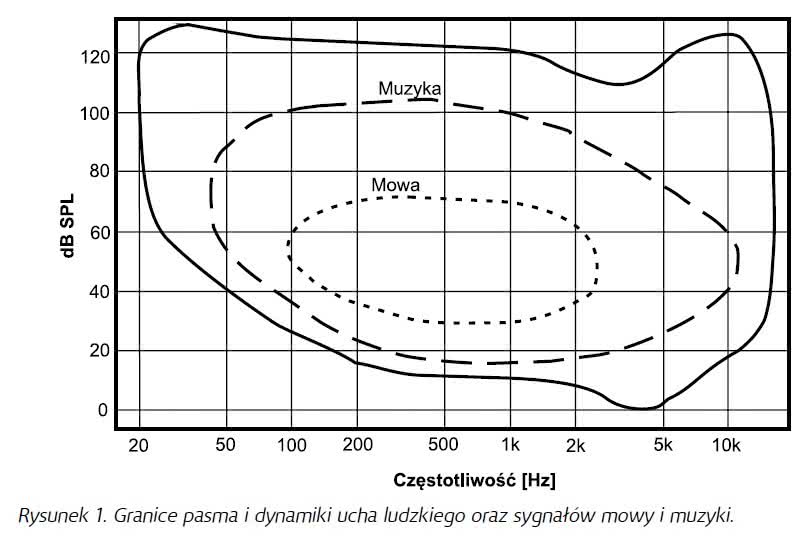
Rysunek 1 prezentuje przybliżone granice pasma i dynamiki sygnałów mowy i muzyki, z którymi możemy się spotkać w salach koncertowych oraz w komunikacji typu face-to-face. Zewnętrzna granica (linia ciągła) określa zakres zdolności słyszenia młodego (bowiem z biegiem lat obszar ten ulega zawężeniu) człowieka z prawidłowym słuchem. Obszar ten ograniczony jest dwiema krzywymi – od dołu dolną granicą słyszalności lub progiem słyszenia (minimalne wartości ciśnień akustycznych dźwięków, przy których ucho zaczyna odbierać wrażenia dźwiękowe), zaś od góry progiem słyszenia bolesnego lub górną granicą słyszalności (ciśnienia wywołujące wrażenie bólu). Wewnątrz tego obszaru mamy zakresy zajmowane przez muzykę i mowę – chodzi tu o „akustyczne” sygnały mowy i muzyki, czyli naturalne (nienagłośnione), przy czym w stosunku do zakresu słyszalności muzyka zajmuje bardziej ograniczony zasięg, szczególnie przy wyższych częstotliwościach, a mowa mieści się w jeszcze mniejszym zakresie.
Gdybyśmy dokonali analizy skumulowanego sygnału mowy z wykorzystaniem oktawowego analizatora widma, zauważylibyśmy, że widmo sygnału mowy przeciętnego człowieka wygląda mniej więcej tak, jak na rysunku 2.
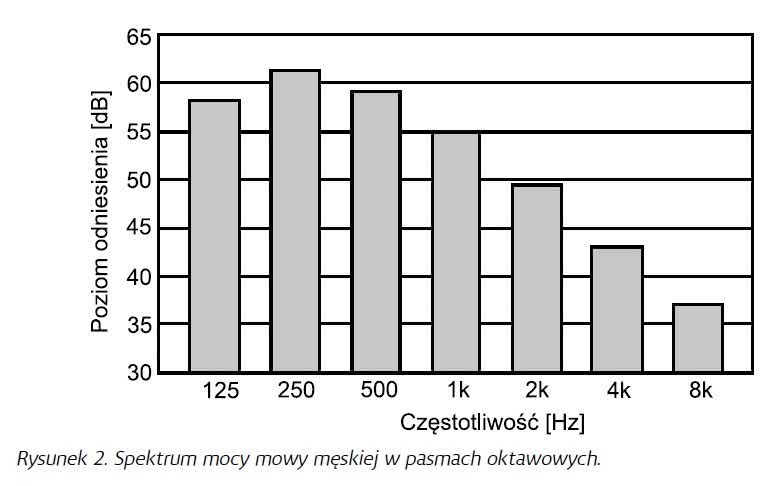
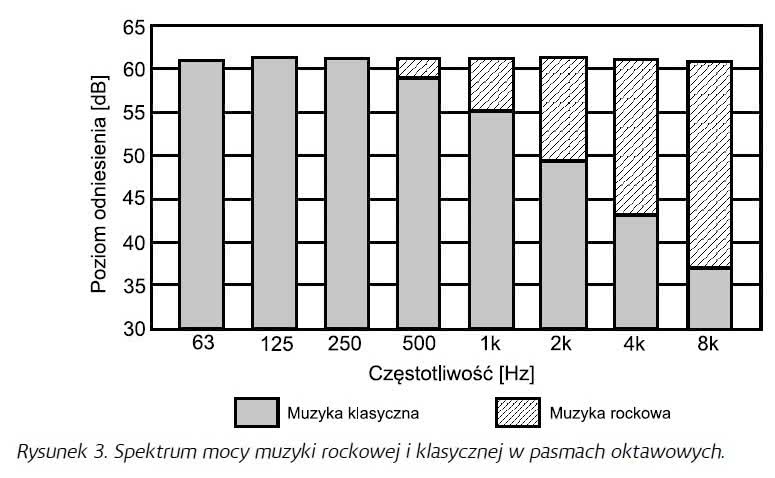
Widmo mocy sygnału mowy osiąga swoje maksymalne wartości w oktawie 250 Hz, opadając zarówno poniżej, jak i powyżej tego pasma, przy czym spadek w zakresie częstotliwości powyżej 1 kHz odpowiada mniej więcej nachyleniu 6 dB/oktawę. Dla porównania na rysunku 3 mamy widmo muzyki rockowej i klasycznej. Zauważmy, że o ile w przypadku muzyki rockowej rozkład mocy jest mniej więcej stały w całym zakresie badanego pasma (63 Hz-8 kHz), o tyle muzyka klasyczna pod względem widma w zakresie częstotliwości średnich i wyższych przypomina to z rysunku 2, a więc widmo sygnału mowy.
Znacząco inaczej od normalnego rozkładu mocy sygnału mowy wygląda, cały czas trzymając się analizy w pasmach oktawowych, wpływ mocy tego sygnału na zrozumiałość mowy. Co prawda taki rozkład ma niewiele wspólnego z naturalnym brzmieniem mowy ludzkiej, jednak z drugiej strony wcale nie jest to takie konieczne do poprawnego zrozumienia, co dana osoba do nas mówi. Fakt ten np. został wykorzystany w telefonii, gdzie pasmo przesyłanego sygnału jest ograniczone do zakresu 300 Hz-3 kHz.
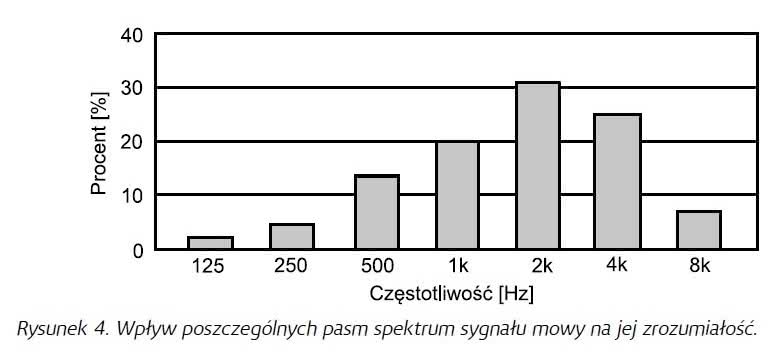
Jak widać na rysunku 4, pasmo z zakresu 1-4 kHz jest tutaj dominujące, i to wyjaśnia, dlaczego w bardzo hałaśliwym otoczeniu system nagłośnieniowy jest często ograniczany właśnie do tego pasma. Oczywiście nam zależy, aby mowa brzmiała zarówno naturalnie, jak i zrozumiale, i jest to oczywiście jak najbardziej możliwe, ale w sytuacji gdy tzw. poziom tła jest odpowiednio niski.
Najlepsze warunki do uzyskania wiernie brzmiącego sygnału mowy są wtedy, gdy poziom tła, a więc mówiąc inaczej hałas otoczenia, jest poniżej 25 dB w stosunku do naszego sygnału użytecznego (mowy). Jeśli różnica ta jest nie większa niż 15 dB, większość odbiorców nie ma większych problemów ze zrozumieniem mówcy, jednak część z nich może narzekać na zbyt wysoki hałas otoczenia. Jeśli różnica ta zmniejszyłaby się jeszcze bardziej, nastąpiłoby znaczące pogorszenie zrozumiałości, co z kolei spowodowałoby konieczność podniesienia poziomu sygnału użytecznego (np. przez jego większe wzmocnienie). Nie można jednak tego robić bez końca. Dlaczego?
Zadajmy sobie pytanie, kiedy mowa jest zbyt głośna? Normalna rozmowa dwóch ludzi twarzą w twarz jest na poziomie 60-65 dB SPL (nie dotyczy wymiany zdań z teściową oraz dyskusji z szefem o podwyżce). Z drugiej strony większość systemów rozgłoszeniowych pracuje w zakresie 70-75 dB SPL. Jeśli poziom nagłaśnianego sygnału mowy wzrośnie powyżej 85 czy 90 dB SPL, poskutkuje to tylko niewielkim wzrostem zrozumiałości, a jednocześnie większość słuchaczy będzie odbierać go jako zbyt głośny. Przy jeszcze wyższych poziomach nie tylko nie zyskujemy na zrozumiałości mowy, ale wręcz zaczyna ona spadać, nie mówiąc już o tym, że słuchacze będą czuć się „osaczeni” dźwiękiem o zbyt dużym poziomie. Zależność tę pokazuje wykres na rysunku 5.
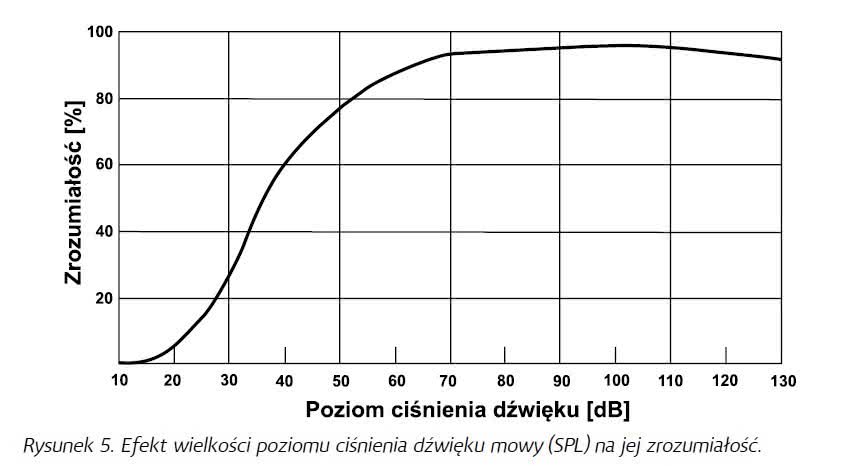
Można z niego odczytać, jaki zakres SPL nagłaśnianego sygnału mowy jest optymalny. Dla systemów rozgłoszeniowych idealny poziom nagłaśnianej mowy w cichym otoczeniu powinien utrzymywać się w zakresie 65-75 dB. Jeśli poziom tła wzrasta, wzmocniony powinien być też sygnał użyteczny, tak aby uzyskać przynajmniej 15-decybelowy odstęp od tła, i np. na dworcach czy w terminalach w czasie szczytu, kiedy hałas otoczenia dochodzi do 65 dB, poziom nadawanych komunikatów głosowych powinien mieć minimalny poziom 80 dB w celu dobrej ich zrozumiałości przez odbiorców. Najgorzej sytuacja przedstawia się na stadionach oraz innych ośrodkach sportowych, gdzie hałas wywoływany przez kibiców może w szczytowych momentach osiągać 90-95 dB, co w zasadzie uniemożliwia czytelne przekazanie informacji w takich sytuacjach. Należy wtedy wstrzymać się z odczytywaniem istotnych informacji aż do momentu, gdy rozentuzjazmowany tłum trochę „odpuści” i poziom tła spadnie poniżej 80 dB.
A co w sytuacji, gdy wzmacniacze mamy już odkręcone „na full” i wysterowane również „na maksa”, a komunikaty z ledwością przebijają się przez ogólnie panujący hałas? Podgłaśnianie źródła sygnału nic nam nie da, gdyż zamiast zwiększyć poziom i tym samym zrozumiałość, spowodujemy zmniejszenie czytelności przekazu, gdyż wzmacniacz, lub nawet jeszcze przedwzmacniacz (mikser), zacznie się przesterowywać. Nie trzeba od razu załamywać rąk i narzekać „gdybym miał mocniejsze końcówki...”, ale najpierw przyjrzeć się naturze wzmacnianego sygnału.
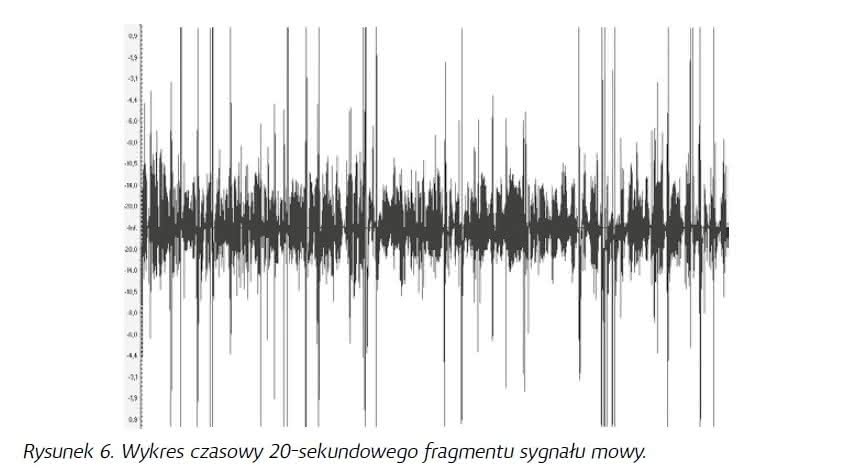
Jeśli bowiem prześledzilibyśmy przebieg czasowy np. 20 s typowego sygnału mowy (rysunek 6), zauważymy, że średnia wartość tego sygnału jest mocno skupiona wokół osi 0 dB i tylko czasami występują wyższe „piki”, przy czym wartość maksymalną osiągają one tylko okazjonalnie. Jeśli taki sygnał podamy na 100-watowy wzmacniacz obciążony impedancją 8 Ω, uzyskamy rozkład sygnału w funkcji napięcia wyjściowego wzmacniacza przedstawiony na rysunku 7. Widać z niego wyraźnie, że gdy pełny zakres zamian sygnału na wyjściu wzmacniacza wynosi ±40 V, średnio nasz sygnał będzie mieścił się w zakresie ±10 V, tylko okazjonalnie przekraczając ten poziom.

Różnica w poziomach tych napięć wynosi 12 dB, co przekłada się na stosunek mocy sygnału wyjściowego równy 16:1. Oznacza to, że przez znaczną część czasu trwania naszego sygnału wykorzystywana jest tylko 1/16 nominalnej mocy wzmacniacza, czyli 6,3 W! Sami przyznacie, że nie jest to zbyt ekonomiczne, a z drugiej strony już wiadomo, dlaczego – pomimo tego że mamy maksymalnie wysterowany i odkręcony wzmacniacz – poziom SPL transmitowanego sygnału jest lichy.
Winę za to ponosi duża wartość tzw. Crest Factor, czyli współczynnika kształtu definiowanego jako stosunek wartości szczytowej amplitudy do wartości RMS. Crest Factor dla sygnału sinusoidalnego wynosi 3 dB, bo taka jest różnica pomiędzy wartością szczytową a RMS dla sinusoidy. Jak łatwo się domyślić, dla sygnału prostokątnego współczynnik kształtu przyjmuje wartość 0 dB, i w kwestii ekonomicznego wykorzystania wzmacniacza sygnał prostokątny jest najbardziej „wydajny”. Z kolei „nasz” sygnał z rysunku 7, jak już wspomniałem wcześniej, charakteryzuje się stosunkiem sygnału szczytowego do średniego równym 12 dB, i właśnie taki jest jego Crest Factor.
Co więc możemy zrobić, aby nasz sygnał nie był wzmocniony tylko o te marne 6 W z groszem, ale na tyle, aby był zrozumiały i czytelny? Wyjścia są dwa:
– albo wymienić wzmacniacz na mocniejszy, np. 200 W – wtedy wzmocnimy nasz sygnał o ok. 12,5 W, co jednak nie rozwiązuje sprawy mało efektywnego wykorzystania wzmacniacza,
– zmniejszyć stosunek sygnału szczytowego do średniego do mniej niż 12 dB.
Drugie rozwiązanie wydaje się być bardziej ekonomicznie uzasadnione, tylko jak tego dokonać? Trzeba skorzystać z dobrodziejstw oferowanych nam przez procesory dynamiczne, i np. korzystając z limitera ograniczyć sygnał na wyjściu o 3,5 dB. Skutkiem tego uzyskamy przebieg taki, jak na rysunku 8, w którym zakres średni napięć na wyjściu wzrósł nam do ±15 V, co przekłada się na wzrost mocy do 14 W.

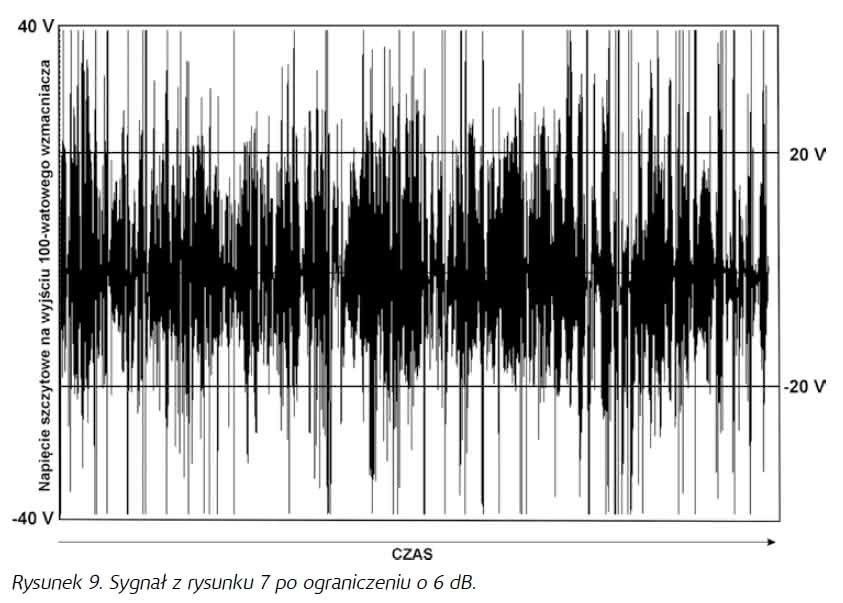
Jeśli ograniczymy nasz sygnał o kolejne 2,5 dB, uzyskamy Crest Factor na poziomie 6 dB, co przełoży nam się na średnią moc na wyjściu równą 25 W (napięcie wyjściowe ±20 V – rysunek 9). Już jest znacznie lepiej, ale czy nie jest to aby słyszalne?
Oczywiście każda zmiana dynamiki sygnału, a więc stosunku najgłośniejszych do najcichszych dźwięków, zaburza jej naturalność brzmienia i dla wprawnego ucha jest słyszalna bez większego problemu. Jednak odpowiednio dokonana kompresja (czy też ograniczenie) sygnału nie wprowadza aż takiej degradacji, aby mowa brzmiała nienaturalnie i niezrozumiale – wprost przeciwnie, dzięki podniesieniu średniego poziomu głośności zyskujemy na zrozumiałości. W standardowych aplikacjach transmisji mowy nie powinno się przekraczać 12 dB, jeśli chodzi o ograniczenie sygnału za pomocą limitera. Nieco inaczej wygląda to w przypadku muzyki, gdzie stosuje się często wyższy stopień ograniczenia, a w zasadzie kompilację ograniczenia i kompresji.
Poprawnie zaprojektowaliśmy ścieżkę sygnału, dopasowali poziomy operacyjne współpracujących ze sobą urządzeń (o poziomach operacyjnych pisaliśmy jakiś czas temu i mam nadzieję, że temat ten nie jest Wam obcy), „podrasowli” odpowiednio nasz sygnał, zwiększając jego poziom średni, i prawidłowo wysterowali urządzenia, a jednak w dalszym ciągu coś jest (a w zasadzie może być) nie tak. A może by tak przyjrzeć się wzmacniaczowi? Jak zapewne wiemy, w systemach instalacyjnych praktycznie nie stosuje się „zwykłych” połączeń wzmacniacz-głośnik, tj. niskonapięciowych – linie wysokonapięciowe to norma. Taki system dystrybucji sygnału stawia przed wzmacniaczem konieczność „wyprodukowania” nie tylko odpowiedniej mocy, ale i napięcia wyjściowego. Wiele obecnie stosowanych wzmacniaczy, zwłaszcza tych o większej mocy, jest w stanie wytworzyć wymagane napięcie wyjściowe o wartości 70 V (a konkretnie 70,7 V) lub 100 V bez żadnych dodatkowych urządzeń. Jednak te o niższych mocach, rzędu 100 W, nie obejdą się bez „pomocy” ze strony transformatora podwyższającego napięcie wyjściowe końcówki do wymaganej wartości. O ile jednak transformator we wzmacniaczu będzie lub nie, o tyle w głośniku bez niego już się nie obejdzie – tym razem będzie on miał za zadanie obniżyć owe napięcie. I właśnie tutaj może pojawić się problem, który zwie się
skutkujące tym, że zamiast wysokiej impedancji, jaką przy normalnej pracy reprezentuje transformator, staje się on po prostu zwarciem lub stanem bliskim zwarcia. Czym to się kończy, nie muszę chyba nikogo uświadamiać – w najlepszym przypadku drastycznym pogorszeniem jakości odtwarzanego przez głośnik dźwięku, w najgorszym spaleniem wyjścia wzmacniacza. Jak może dojść do nasycenia (saturacji) transformatora? Napięcia – odpowiednio dla rodzaju linii – 70,7 V i 100 V są wartościami maksymalnymi, jeśli więc je przekroczymy, może to spowodować właśnie nasycenia transformatora głośnikowego. System dystrybucji sygnału powinien być tak zaprojektowany, aby pracować w zakresie 50-75% swoich możliwości (czyli dla linii 100 V w zakresie od 50 do 75 V), co zapewni nam odpowiedni headroom, czyli odstęp od „przesterowania” transformatora głośnikowego, a więc i jego nasycenia.

To nie koniec problemów z transformatorami – w nasycenie może również wejść transformator podwyższający napięcie wyjściowe wzmacniacza (szczególnie jeśli mamy oddzielny wzmacniacz i oddzielny transformator). Może się to stać, jeśli podamy na niego zbyt dużą moc. Trzeba więc zwracać uwagę na dopasowanie mocy wyjściowej końcówki do mocy, jaką może przyjąć uzwojenie pierwotne transformatora (trzeba znać jego impedancję, która przeważnie wynosi 4 lub 8 Ω). Z racji tego, że znaczna część głośników stosowanych w instalacjach transmisji mowy i tak nie przenosi poniżej 100 Hz, dobrze jest jeszcze przed wzmacniaczem zastosować filtr górnoprzepustowy o częstotliwości z zakresu 80-120 Hz, co, po pierwsze, uchroni nas w pewnym stopniu przed nasyceniem transformatora podwyższającego, a po drugie wprowadzi pewne oszczędności energii – jak wiadomo, większość mocy przenoszą najniższe częstotliwości, a skoro i tak nie będą odtwarzane, to po co niepotrzebnie pompować je do transformatorów i głośników.
Mam nadzieję, że tych kilka porad pozwoli Wam projektować i wykonywać instalacje, z których zawsze będziecie mogli być tylko dumni, gdyż będą „sumiennie” wypełniać powierzone im zadania – zrozumiale przekazywać wszelkie komunikaty, a przy okazji wprowadzać miły nastrój, emitując muzykę, która faktycznie brzmi jak muzyka, a nie jak skrzypienie zardzewiałego kołowrotka od studni.
Piotr Sadłoń
Przy tworzeniu artykułu autor korzystał z artykułów Jeffa Kuellsa oraz Johna Eargle i Chrisa Foremana.


