









X4L - wzmacniacz z DSP z serii X
Biznes „nagłośnieniowy” – w porównaniu z innymi dziedzinami techniki (np. przemysłem samochodowym, czy ...

W ubiegłym miesiącu powiedzieliśmy co nieco o rozchodzeniu się fal dźwiękowych w pomieszczeniu zamkniętym, o tym jak wygląda w nim wykres narastania i zanikania dźwięku (w skali liniowej i logarytmicznej), aż wreszcie dotarliśmy do tematu pogłosu.
Wspomniałem wtedy o czasie pogłosu, ale na konkrety dotyczące tego tematu nadszedł czas właśnie teraz. Przypomnijmy sobie to, co już wiemy o
Czas pogłosu jest ważnym parametrem określającym jakość akustyczną wnętrz, a więc również w istotny sposób wpływającym na odbiór mowy i muzyki w pomieszczeniach. Zależy on od liczby odbić fal dźwiękowych w ciągu 1 s, a więc od średniej długości swobodnej drogi fali między dwoma kolejnymi odbiciami i od ilości energii pochłoniętej w trakcie jednego odbicia. W pomieszczeniach dużych, gdzie średnia długość swobodnej drogi jest duża, a liczba odbić w ciągu 1 sekundy jest mała, a do tego ściany są pokryte materiałem słabo pochłaniającym energię fal akustycznych, czas pogłosu jest długi. Analogicznie w pomieszczeniach małych, o powierzchniach silnie pochłaniających, czas pogłosu będzie mały.
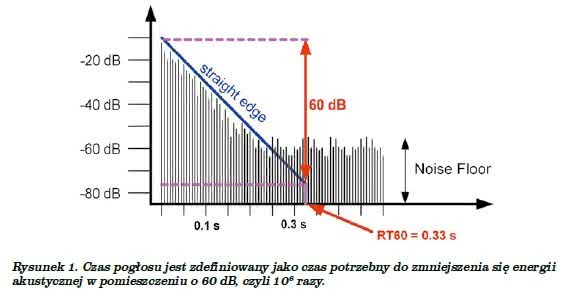
Czas pogłosu jest to czas potrzebny do zmniejszenia się energii w pomieszczeniu o 60 dB, czyli 106 razy (1.000.000 czyli milion razy) – przedstawia to rysunek 1. Owe 60 decybeli wzięło się stąd, iż Sabine – który jest twórcą tej definicji – stosował do swoich pomiarów źródło dźwięku o częstotliwości 512 Hz, które dawało w stanie ustalonym poziom energii o 60 dB wyższy od poziomu odpowiadającemu dolnej granicy słyszalności.
Czas pogłosu pomieszczenia można orientacyjnie wyznaczyć ze wzorów:
a) dla pomieszczeń niewytłumionych (o małej chłonności akustycznej), tj. αśr ≤ 0,2, o równomiernie rozłożonej chłonności i o dużym czasie pogłosu:

b) dla pomieszczeń silnie wytłumionych, tj. αśr > 0,2, o równomiernie rozłożonej chłonności i o małym czasie pogłosu:

gdzie:
T – czas pogłosu pomieszczenia [s]
V – objętość [m3]
S – powierzchnia ograniczająca pomieszczenie [m2]
A – chłonność pomieszczenia [m2]
A’ – chłonność skorygowana (A’ = α’śrS)
α – współczynnik pochłaniania dźwięku
α’ – współczynnik skorygowany (dla α > 0,2) z rysunku 2.

Możemy też sami obliczyć α’śr ze wzoru

wtedy wzór z podpunktu b) przyjmie postać

Jest też wzór „autorstwa” Knudsena, w którym uwzględnione jest dodatkowo pochłanianie dźwięku spowodowane obecnością pary wodnej w powietrzu. Wygląda on następująco:

gdzie:
m – współczynnik zależny od względnej wilgotności powietrza i częstotliwości.
Pochłanianie powietrza przez cząsteczki pary wodnej jest szczególnie duże dla fal dźwiękowych o dużej częstotliwości i może wynosić – w dużych pomieszczeniach – do 30% całkowitego pochłaniania.
Powyższe wzory teoretycznie pozwalają na obliczenie z dużą dokładnością czasu pogłosu pomieszczenia, gdy znane są jego wymiary oraz średni współczynnik pochłaniania. Niestety tylko teoretycznie, bo wyznaczenie średniego współczynnika pochłaniania nie jest wcale taką prostą sprawą. Natomiast z punktu widzenia projektowania wnętrz wzór na czas pogłosu posłużyć może do obliczenia średniego współczynnika pochłaniania dla najkorzystniejszego czasu pogłosu projektowanego/adaptowanego pomieszczenia.
Mając obliczony średni współczynnik pochłaniania należy przede wszystkim obliczyć całkowitą chłonność pomieszczenia ze wzoru:
A = α·S
która musi być równa sumie chłonności powierzchni ścian, osób i przedmiotów znajdujących się w pomieszczeniu, czyli:

Zadaniem akustyka jest teraz taki dobór materiałów dźwiękochłonnych, o takim współczynniku pochłaniania i takiej powierzchni, aby otrzymać pożądaną wartość A. Potrzebna do tego jest wiedza o współczynnikach pochłaniania różnorakich materiałów, stosowanych w konstrukcji i adaptacji wnętrz, oraz wartości chłonności wprowadzanych przez osoby i przedmioty, które będą się znajdowały w tym pomieszczeniu, a także ich charakterystyki w funkcji częstotliwości.
Z tego krótkiego opisu wszystko wygląda łatwo, ale bynajmniej tak nie jest. Akustyk musi zadbać nie tylko o to, aby czas pogłosu w sali był właściwy, nie tylko aby jego charakterystyka w funkcji częstotliwości była odpowiednia, ale również aby rozkład pola akustycznego był adekwatny do potrzeb – w jednym przypadku będzie wymagany jak najbardziej równomierny (np. studio nagrań), w innym odpowiednie kierowanie fal akustycznych (np. teatry, opery), co będzie wymagało odpowiedniego rozmieszczenia w sali powierzchni pochłaniających i odbijających, a do tego jeszcze powierzchni i ustrojów rozpraszających. Trzeba mieć nie tylko dużą wiedzę teoretyczną, ale również doświadczenie, a i tak efekt końcowy przeważnie – w mniejszym lub większym stopniu – różni się z założonego. Zbyt wiele czynników ma wpływ na ten efekt końcowy, aby dało się to w 100-procentach przewidzieć czy zasymulować w programie predykcyjnym. Nawet stworzenie rzeczywistego modelu w skali (jak to np. miało miejsce podczas projektowania obu sal siedziby Narodowej Orkiestry Symfonicznej Polskiego Radia w Katowicach) również nie gwarantuje 100-procentowej sprawdzalności w warunkach rzeczywistych.
O tym, jaki jest najkorzystniejszy czas pogłosu, albo raczej w jakich granicach powinien on się zawierać, w zależności od zastosowania i kubatury pomieszczenia, będziemy mówić w jednym z kolejnych artykułów.
Wróćmy jeszcze na chwilę do samego pogłosu.
Pogłos nie jest wbrew pozorom prostym, nieskomplikowanym zjawiskiem. „Składa się” z kilku elementów, przedstawionych na rysunku 3.
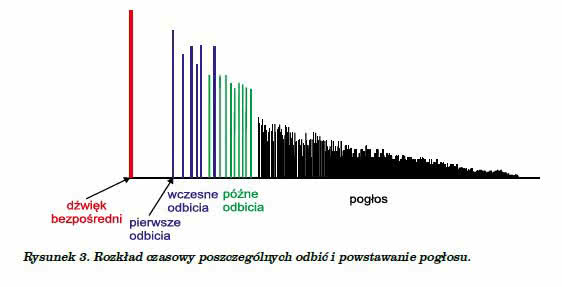
W kolejności dotarcia do słuchacza mamy:
– dźwięk bezpośredni – czyli pierwszy dźwięk, docierający w linii prostej od źródła do słuchacza. Przyczynia się do wrażenia głośności i wyrazistości. Z badań prowadzonych przez Haasa wynika, że o subiektywnym odczuciu kierunku dźwięku decyduje dźwięk bezpośredni i odbicia o opóźnieniu do 1 ms,
– pierwsze odbicie (first reflection) – dźwięk, który odbił się od najbliższej powierzchni odbijającej (najczęściej od podłogi) i dotarł jako pierwszy, po dźwięku bezpośrednim, do słuchacza,
– wczesne odbicia (early reflections) – obejmują dźwięki dochodzące do słuchacza po pojedynczym odbiciu od ścian, podłogi i sufitu. Haas wykazał, że odbicia opóźnione o 20-50 ms dają wrażenie zwiększenia głośności dźwięku bezpośredniego. Aby uzyskać pełnię brzmienia, wczesne odbicia powinny dochodzić z możliwie jak największej liczby kierunków,
– późne odbicia (later reflections) – to dźwięki dochodzące do słuchacza po wielokrotnym (najczęściej podwójnym lub potrójnym) odbiciu od ścian, podłogi i/lub sufitu (rysunek 4),

– pogłos „właściwy” lub pole pogłosowe (reverberant field) – składa się z dużej ilości dźwięków wielokrotnie odbitych (wg. Cremera i Müllera w ciągu sekundy do słuchacza dociera powyżej 2.000 odbić). Odstępy między kolejnymi falami odbitymi są tak krótkie, że pole pogłosowe ma charakter stopniowo zanikającego przedłużenia dźwięku bezpośredniego. Zależnie od współczynników pochłaniania powierzchni pomieszczenia pogłos zanika powoli lub gwałtownie, co przekłada się na czas pogłosu pomieszczenia,
– początkowe opóźnienie (Initial Time Delay Gap lub pre-delay) – to różnica czasu między dotarciem do słuchacza dźwięku bezpośredniego i pogłosu (pola pogłosowego). Od jego wartości zależy subiektywne wrażenie wielkości pomieszczenia. Z badań prowadzonych przez Beranka wynika, że w najlepszych salach koncertowych czas ten dla słuchacza siedzącego w środku sali wynosi od 15 do 30 milisekund. Wynika stąd, że droga przebyta przez falę odbitą powinna być od 5 do 10 metrów dłuższa niż droga przebyta przez falę bezpośrednią. Jeśli wartość pre-delay jest zbyt duża (od 50 do 70 milisekund), słuchacz będzie miał wrażenie przebywania w olbrzymiej przestrzeni. Odbicie docierające z opóźnieniem powyżej 100 ms zostanie odebrane jako echo.
A teraz zapomnijcie o tym, co napisałem powyżej... przynajmniej dla niskich częstotliwości, gdyż opisany wyżej model dotyczy częstotliwości średnich i wysokich – w przypadku dźwięków basowych, niestety, jest jeszcze „gorzej”.
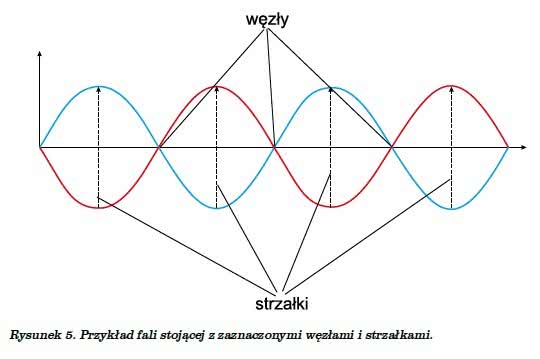
Na początek mała powtórka z fizyki, która będzie nam niezbędna do dalszych rozważań. Czy pamiętamy coś na temat zjawiska fal stojących? Jeśli tak, to małe przypomnienie, a jeśli nie, to będzie okazja czegoś na ten temat się dowiedzieć. Fala stojąca to fala, której pozycja w przestrzeni pozostaje niezmienna. Tyle oficjalna definicja, teraz spróbujemy przetłumaczyć to „z polskiego na nasze”.
Po pierwsze, i bardzo ważne, fala stojąca może wytworzyć się tylko i wyłącznie w ośrodku uformowanym (tj. w takim, który nie zmienia swojego kształtu) i ograniczonym, np. pręt, słup powietrza w rurze czy też drgania powietrza w pomieszczeniu zamkniętym. Fala stojąca jest wynikiem interferencji dwóch fal biegnących w przeciwnych kierunkach, a więc z powodzeniem może powstać w pokoju, sali czy na korytarzu, jeśli na ściany (a także podłogę i sufit) tych pomieszczeń padnie fala akustyczna, która następnie od nich zostanie odbita. Tak po prawdzie, z fizycznego punktu widzenia, idealna fala stojąca wcale nie jest falą – gdyż ta musi podlegać propagacji, czyli rozprzestrzeniać się. Natomiast, jak widzimy, idealna fala stojąca jest stacjonarnymi (cały czas w tych samych punktach) drganiami ośrodka. W przypadkach rzeczywistych zwykle porusza się ona tam i z powrotem w ograniczonym obszarze przestrzeni.
Charakterystycznymi punktami fali stojącej są węzły i strzałki. Miejsca, gdzie amplituda fali osiąga maksima, nazywane są strzałkami, zaś te, w których amplituda jest zawsze zerowa – węzłami fali stojącej (rysunek 5).
Skoro wiemy już co nieco o falach stojących, czas odnieść tę zdobytą lub utrwaloną wiedzę do tematu nas interesującego, czyli
oczywiście w pomieszczeniach zamkniętych.
Jeśli zmierzylibyśmy charakterystykę częstotliwościową dowolnego pomieszczenia – szczególnie dla nas interesujący będzie w tym przypadku zakres najniższych częstotliwości – zauważymy, że nawet dysponując źródłem dźwięku o jak najbardziej płaskiej charakterystyce wynik naszych pomiarów będzie wyglądał niczym przekrój przez jakieś pasmo górskie. Dość znaczne „górki” na charakterystyce przedzielały będą sporej głębokości doliny, a będzie to najbardziej widoczne w najniższych zakresach, czyli poniżej 400 Hz (rysunek 6).
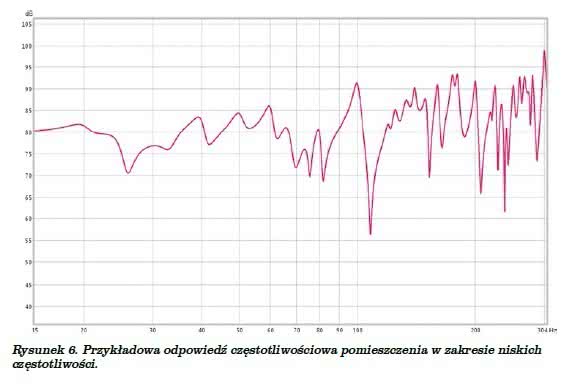
Tak wygląda charakterystyka pomieszczenia zmierzona w jednym konkretnym punkcie, przesuwając się o kilka centymetrów w tę czy inną stronę otrzymamy inny, często drastycznie przebieg. Wynika to właśnie z faktu „obecności” fal stojących, zwanymi modami drgań lub rezonansami pomieszczenia.
Każde pomieszczenie, również i te mające nieparzystą liczbę ścian, rezonuje na wielu częstotliwościach. To, jak „ostre” będą górki na charakterystyce, i jaka będzie różnica poziomów między górkami i dolinami, zależeć będzie od stopnia pochłaniania fal dźwiękowych przez powierzchnie, między którymi tworzą się fale stojące. Pomieszczenie z dużą liczbą mebli tapicerowanych, z dywanami na podłogach, firanami i zasłonami w oknach będzie akustycznie „nieżywe”, na charakterystyce którego różnice między szczytami i dolinami będą relatywnie niewielkie, rzędu 5-10 dB. Pokój czy sala z „gołymi” ścianami będą „żywe” akustycznie, i w tym przypadku różnice między tymi punktami mogą dochodzić do 20 dB i więcej.
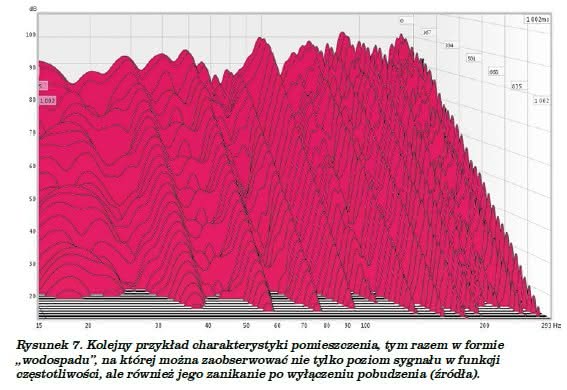
Dla przykładu – pomieszczenie, którego charakterystykę prezentujemy na rysunku 7, charakteryzuje się średnim współczynnikiem tłumienia, rzędu 0,2, co przy danej kubaturze odpowiada czasowi pogłosu w granicach 0,7 sekundy. Na tym wykresie można też zauważyć, iż zanikanie tych częstotliwości jest wydłużone w czasie w stosunku do innych, tak więc pomieszczenie „wybrzmiewa”, czyli rezonuje na tych właśnie częstotliwościach, i stąd nazwa – rezonanse pomieszczenia.
Gdyby fale stojące powstawały między naprzeciwległymi ścianami i tylko dla częstotliwości wynikających ze wzoru:
f = c/2L
gdzie:
f – to częstotliwość tejże fali
c – prędkość dźwięku
L – odległość między ścianami
wtedy pół biedy – w „tradycyjnym”, prostopadłościennym pomieszczeniu byłoby ich tylko 3, czyli nie tak najgorzej. Niestety, nie ma tak łatwo. Nie dość że oprócz częstotliwości podstawowych, wynikających z powyższego wzoru, mamy ich kolejne wielokrotności (2f, 3f, 4f itd.), to jeszcze – jak się okazuje – fale stojące powstają nie tylko przy podwójnym odbiciu, od dwóch ścian, ale i od czterech, a także wszystkich sześciu powierzchni ograniczających (o tym za chwilę).
Widzimy więc, że – biorąc tylko pod uwagę jedną parę ścian – fal stojących wytworzy się kilka albo i kilkanaście (w pomieszczeniu odbicia fal o wyższych częstotliwościach łatwiej stłumić niż fal o częstotliwościach niskich, rzędu kilkadziesiąt- kilkaset herców). Spójrzmy na rysunek 8, przykładowego rozkładu ciśnienia trzech pierwszych modów drgań między dwiema równoległymi powierzchniami.

Mod pierwszy, wynikający ze wzoru poniżej, wystąpi przy częstotliwości 56 Hz, kolejne to podwojenie i potrojenie tej wartości, a więc – odpowiednio – 112 Hz i 168 Hz. Patrząc na ten rysunek możemy wysnuć kilka wniosków:
– poziom ciśnienia akustycznego nie jest równomierny w całym pomieszczeniu,
– pierwszy rezonans (mod) pomieszczenia ma wartość poziomu ciśnienia zbliżoną do zera w środku odcinka łączącego odbijające powierzchni (w centralnym punkcie pomieszczenia), tak samo będzie dla jego nieparzystych harmonicznych,
– dla składowych parzystych odwrotnie, w środku występować będzie maksymalny poziom ciśnienia akustycznego,
– wszystkie mody drgań własnych pomieszczenia mają maksymalną wartość SPL w pobliżu ścian.
To wyjaśnia, dlaczego głośność odtwarzanych basów zmienia się przy zmianie miejsca odsłuchu w danym pomieszczeniu oraz dlaczego w pobliżu ścian basu jest najwięcej.
Idźmy dalej – wszak prostopadłościenne pomieszczenie ma trzy pary powierzchni, między którymi mogą powstawać fale stojące, a więc mamy już trzy zestawy drgań własnych pomieszczenia (mały przykład, dla pierwszych dziesięciu modów drgań, w tabeli poniżej).

Graficznie przedstawia to rysunek 9, gdzie kolorem zielonym zaznaczone są mody drgań dla pierwszej kolumny tabelki (odległość między ścianami 2,5 m), kolorem czerwonym dla drugiej kolumny (odl. 4 m), zaś kolorem niebieskim dla kolumny 3 (odl. 5,8 m). Wykres czarny to suma wszystkich modów, uwzględniająca również interferencje występujące pomiędzy nimi.

Jak widać, uzbierało się tego trochę i, co ciekawe, im wyżej na skali częstotliwości, tym robi się gęściej (to akurat dobrze, ale o tym powiemy przy okazji omawiania sposobów zwalczania niekorzystnego wpływu drgań własnych pomieszczenia na odtwarzany materiał dźwiękowy).
Idźmy dalej.
Jak wspomniałem wcześniej, fala stojąca może tworzyć się nie tylko między dwiema równoległymi powierzchniami (mody osiowe – ang. axial), ale także między czterema (mody styczne – ang. tangential) i sześcioma (mody skośne – ang. oblique) sąsiadującymi powierzchniami. Symbolicznie przedstawia to rysunek 10.
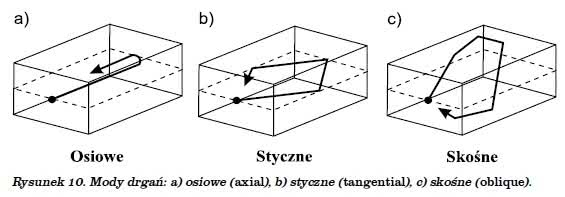
Mody styczne i skośne mają już mniejszy wpływ na „brzmienie” pomieszczenia niż mody osiowe, gdyż dodatkowe odbicia od powierzchni pomieszczenia „osłabiają” falę, tj. poziom ciśnienia akustycznego dla tych dwóch przypadków będzie mniejszy, przy czym najmniej słyszalne są oczywiście drgania skośne. Nie zmienia to wszak faktu, że owych drgań własnych przybywa nam co najmniej drugie tyle niż miałoby to miejsce w przypadku istnienia tylko modów osiowych.
Czy można w jakiś sposób walczyć z rezonansami własnymi pomieszczeń? Powiedzmy sobie szczerze – mody drgań własnych są nie do uniknięcia, i nawet najlepiej zaprojektowane i zaadaptowane akustycznie pomieszczenie nie może poszczycić się ich brakiem. Nie da się więc całkowicie wyeliminować wpływu drgań własnych pomieszczeń na reprodukowany w nich dźwięk, można jednak starać się go minimalizować. O tym jednak opowiemy sobie w jednym z kolejnych artykułów z tej serii.
Piotr Sadłoń
Przy tworzeniu artykułu autor korzystał z publikacji „Akustyka architektoniczna” Jerzego Sadowskiego oraz „Podstawy elektroakustyki” Zbigniewa Żyszkowskiego.


