









X4L - wzmacniacz z DSP z serii X
Biznes „nagłośnieniowy” – w porównaniu z innymi dziedzinami techniki (np. przemysłem samochodowym, czy ...

Słuchając muzyki dobrze jest wiedzieć, o czym wokalista/wokalistka śpiewa, prawda?
Nawet jeśli śpiewa w języku dla nas niezrozumiałym, nie możemy zakładać, że cała reszta świata również nie ma pojęcia, co człowiek po drugiej stronie mikrofonu próbuje przekazać.
Tak więc niezależnie od tego, czy piosenka jest śpiewana po polsku, angielsku, czesku, czy arabsku, zadaniem człowieka odpowiedzialnego za przekazywanie „w lud” wysiłków śpiewającego artysty, a więc realizatora nagrań (w przypadku płyt CD, DVD i innych form rejestracji) czy realizatora dźwięku (w przypadku koncertów, transmisji telewizyjnych, radiowych itp.) jest zadbanie o to, aby odbiorca mógł owego artystę zrozumieć. No, z tym to jest u nas różnie, szczególnie jeśli chodzi o przekaz „na żywo”, czyli nagłaśnianie koncertów różnorakich wykonawców. Ale nie mam tutaj zamiaru biadolić „nad zastaną rzeczywistością”, ale spróbować przekazać kilka informacji, który pomogą ten stan zmienić na lepsze.
Nasz głos to nic innego, jak każde inne źródło dźwięku, które musimy nagrać/ nagłośnić w odpowiedni sposób, tak aby nie zatracić jego charakteru, a jednocześnie sprawić, aby dobrze „wpasował” się w ogólny miks (jeśli jest to wokal z towarzyszeniem instrumentów lub innych wokali), no i był – o czym wspomniałem na początku – słyszalny i zrozumiały. Zrozumiałość nabiera jeszcze większego znaczenia w przypadku nagłaśniania mowy – nikt nie lubi się „produkować”, podczas gdy odbiorcy nie są w stanie zrozumieć, „co autor ma na myśli” (i nie chodzi mi tu o pokrętne formułowanie wypowiedzi, będące cechą większości polityków, ale o sam fakt niemożliwości „fizycznego” zrozumienia przemawiającego). Zastanówmy się więc, jakimi cechami, jako źródło dźwięku, charakteryzuje się głos ludzki, które mają największy wpływ na to, czy jesteśmy w stanie zrozumieć, co dany człowiek mówi/śpiewa, oraz – na koniec – jak wykorzystać tę wiedzę do poprawnego (w sensie technicznym) przekazania słów człowieka z mikrofonem jego potencjalnym odbiorcom.
Pierwszy aspekt, który rozważymy to
Poziom dźwięku
w dość bezpośredni sposób związany z wrażeniem głośności, co nas najbardziej w tym momencie interesuje. Wiadomo bowiem, że im człowiek mówi ciszej, tym gorzej go słychać i tym trudniej zrozumieć, co mówi lub śpiewa. Ale, wbrew pozorom, zbyt donośny głos wydobywający się z głośników bynajmniej wcale nie pomaga zrozumieć wypowiadane czy wyśpiewywane słowa – zaraz do tego dojdziemy.

Poziom dźwięku głosu ludzkiego może zmieniać się w bardzo szerokim zakresie – od szeptu po głośny krzyk (wrzask). Oczywiście dla każdego człowieka jest sprawą indywidualną, jak szeroki będzie to zakres, stąd w tabeli 1 podane są średnie wartości SPL dla czterech różnych poziomów głośności „wyprodukowanych” przez dorosłego człowieka. Wartości SPL są podawane w kilku różnych odległościach od źródła, od 0,5 do 5 m. Trzeba dodać, o czym przed chwilą wspomniałem, że optymalny poziom pozwalający na najlepsze zrozumienie osoby, która do nas mówi, koresponduje z wartością normalnej rozmowy słyszanej z odległości 1 m od rozmówcy, czyli – patrząc na naszą tabelkę – mieści się w zakresie 55-65 dB (odniesione do wartości ciśnienia akustycznego równego 20 μPa). Jak widać z wyników pomiarów zaprezentowanych w tabeli 1, różnica między normalną mową a krzykiem wynosi ok. 20 dB.
Współczynnik kształtu (crest factor)
Należy podkreślić, że wartości w tabeli 1 są średnimi poziomami RMS ciśnienia dźwięku, a nie poziomami szczytowymi. Typowo szczyty sygnałów mowy będą o 18-21 dB większe niż poziomy RMS. Relację między poziomem średnim a szczytowym określa nam tzw. crest factor, czyli po naszemu współczynnik kształtu – bardzo ważny parametr, zarówno w nagraniach, jak i w nagłaśnianiu. Dzięki niemu możemy przewidzieć, jakim headroomem powinien charakteryzować się system nagłośnieniowy (czy też system nagraniowy w przypadku rejestracji), aby bez zniekształceń przenieść najwyższe „piki” sygnału, które – jak w przypadku mowy – mogą być znacząco wyższe od średnich poziomów. Ilustruje to rysunek 1, w którym czerwoną linią zaznaczono poziom średni, podczas gdy szczyty są znormalizowane do wartości 0 dB (dokładnie do -0,1 dB).

W związku z powyższym należy mieć na uwadze, iż poziom ciśnienia dźwięku głośno śpiewającego wokalisty/wokalistki (czy też krzyczącej osoby) może w okolicy ust osiągnąć wartość 130 dB (w odniesieniu do ciśnienia 20 μPa), a poziom szczytowy może w takim przypadku przekroczyć 150 dB!
Spektrum sygnału mowy
Spektrum, albo inaczej widmo, sygnału mowy pokrywa znaczną cześć całego akustycznego pasma częstotliwości. Mowa ludzka składa się, o czym mam nadzieję pamiętamy ze szkoły podstawowej, z głosek dźwięcznych i bezdźwięcznych. Te pierwsze, w uproszczeniu, generowane są głównie przez struny głosowe, a następnie filtrowane przez układ jamy ustnej, przez którą przechodzą. Szept jest głosem bezdźwięcznym, aczkolwiek układ jamy ustnej, który bierze udział w formowaniu głosek dźwięcznych, w tym przypadku również pracuje – jedynie struny głosowe w tej sytuacji „próżnują”. Dlatego też charakterystyki głosek dźwięcznych występują również podczas szeptu, dzięki czemu wciąż jesteśmy w stanie rozróżnić głoski „a”, „e”, „i”, „o”, „g”, „j”, „m”, „r”, „z” itd. Generalnie częstotliwość podstawowa – zwana też wysokością tonu lub po prostu f0 – leży w zakresie 100-120 Hz w przypadku mężczyzn, ale również mogą występować przypadki, gdy podstawowa częstotliwość głosek dźwięcznych będzie spoza tego przedziału, tak powyżej, jak i poniżej. F0 dla kobiet najczęściej lokuje się mniej więcej oktawę wyżej (200- 250 Hz), zaś w przypadku dzieci f0 wypada w okolicy 300 Hz.
Głoski bezdźwięczne powstają, gdy więzadła głosowe są rozsunięte i powietrze z płuc swobodnie przechodzi przez otwartą głośnię. Formowane więc są przez blokowanie powietrza w różnych częściach toru głosowego – np. za pomocą języka lub ust (p, k, t) – lub poprzez filtrowanie szumowego strumienia powietrza (c, f, h, s). Patrząc z częstotliwościowego punktu widzenia, głoski bezdźwięczne najczęściej lokują się w okolicach 500 Hz.
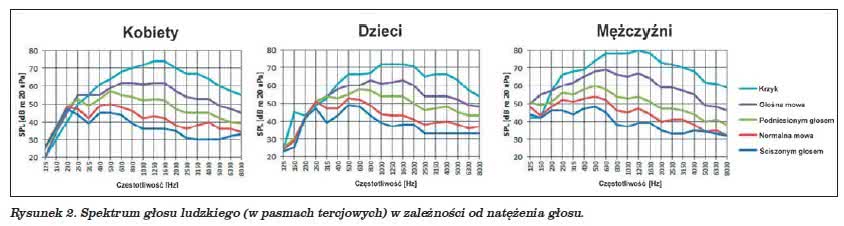
Przy normalnej intensywności wokalu czy głosu mówionego energia głosek dźwięcznych dość raptownie maleje powyżej 1 kHz. Należy jednak zauważyć, że najwyższe wartości SPL spektrum sygnału mowy znajdują się jedna-dwie oktawy wyżej, na skali częstotliwości (patrz rysunek 2). Zwróćmy też uwagę, iż niemożliwe jest zwiększenie poziomu głośności głosek bezdźwięcznych równie mocno, jak dźwięcznych (nie jesteśmy w stanie tak samo głośno krzyknąć „p” czy „c”, jak np. „a” „o”). W praktyce oznacza to, że nie uzyskamy zwiększenia zrozumiałości mowy poprzez wykrzyczenie słowa czy zdania, w porównaniu do normalnej mowy – oczywiście w sytuacji, gdy poziom tła jest niezbyt istotny.
Formanty
Kiedy słuchamy dwoje lub więcej osób, mówiących czy śpiewających te same samogłoski, o takich samych częstotliwościach podstawowych (f0), samogłoski te będą rozpoznane jako takie same we wszystkich przypadkach, pomimo tego iż najprawdopodobniej będą się różnić, patrząc na to z punktu widzenia dźwięku (ich widma częstotliwościowe będą inne). Z drugiej strony patrząc, pozwala nam to rozróżnić mówców, pomimo tego że wypowiadają te same głoski i to nawet starając się zachować ich tę samą podstawę częstotliwościową. Odpowiedzialne za to, iż niezależnie od barwy głosu danej osoby dana głoska zawsze brzmi tak samo, są formanty, których fenomen można wytłumaczyć jako akustyczne filtrowanie spektrum generowanego przez struny głosowe.
Generalnie mówiąc, w przypadku języków europejskich, w tym również polskiego (można rzec, tym bardziej polskiego), kluczowe znaczenie, jeśli chodzi o zrozumiałość mowy/wokalu, ma poprawne „odszyfrowanie” spółgłosek.
Ważne częstotliwości
Istotność spółgłosek, szczególnie tych bezdźwięcznych, w językach europejskich ilustruje rysunek 3.

Pasmo sygnału mowy zostało odfiltrowane w jednym przypadku za pomocą filtru górnoprzepustowego (kolor niebieski), a w drugim za pomocą filtru dolnoprzepustowego (kolor czerwony). Wykres pokazuje, jakie wartości przyjmuje zrozumiałość w przypadku stosowania różnych wartości częstotliwości granicznej filtrów. I tak np. używając filtru HP (high pass, czyli górnoprzepustowego), który odfiltrowuje wszystko poniżej 100 Hz, w dalszym ciągu uzyskujemy 100-procentową zrozumiałość. Taki sam filtr nastrojony na 500 Hz wciąż pozwala bez większych problemów zrozumieć mówcę, bowiem zrozumiałość spada tylko o 5%, a nawet filtracja przy 1 kHz zmniejszy zrozumiałość do przyzwoitych 85%. Jednak zwiększając częstotliwość od tego miejsca, nawet nieznacznie, zrozumiałość zaczyna raptownie maleć – dla 2 kHz będzie to już tylko 40 procent, a dla 3 kHz – niespełna 10%. Trochę gorzej wygląda to w przypadku filtracji dolnoprzepustowej, gdzie przy 1 kHz zrozumiałość osiąga już ledwo 40%, a dopiero powyżej 4 kHz osiągamy przyzwoite rezultaty, tzn. powyżej 90 %.
Widać stąd, że częstotliwości z zakresu 1-4 kHz odgrywają bardzo istotną rolę, jeśli chodzi o zrozumiałość mowy/ wokalu.
Szum tła
Nikogo chyba nie zdziwi, że szum tła ma wpływ na postrzeganie zrozumiałości sygnału mowy. W takiej sytuacji każdy inny sygnał, oprócz mowy/wokalu (w tym muzykę), możemy traktować jako szum, czyli coś niepożądanego w danym momencie. W przypadku audytoriów, sal wykładowych czy konferencyjnych generatorem takiego szumu może być system określany z angielska HVAC, czyli systemy grzewcze, wentylacyjne i klimatyzacyjne (Heating, Ventilation, Air Conditioning) lub inne hałaśliwe (mniej lub bardziej) instalacje, czyniące sygnał mowy mniej zrozumiałym. Także sami widzowie/ słuchacze/uczestnicy mogą niejednokrotnie znacząco podnieść szum tła, generując całkiem spory szum – w zależności od liczby osób i ich zdyscyplinowania. W końcu sama muzyka, sącząca się w tle lub ilustrująca jakąś prezentację, prelekcję, wykład, medytację czy modlitwę – o czym już wspomniałem – musi być umiejętnie poziomowana, aby nie narobić więcej szkody niż pożytku.

Na rysunku 4 zrozumiałość mowy jest przedstawiona w funkcji poziomu sygnału mowy, dla kilku wartości stosunku sygnał/ szum (S/N). Najniższa krzywa pokazuje, że mowa może być wciąż w dużym stopniu zrozumiała nawet w sytuacji ujemnego S/N, co w tym przypadku oznacza, że poziom szumu tła jest o 10 dB wyższy od sygnału użytecznego. Jednak – co już kilkakrotnie było wspomniane – najwyższą zrozumiałość uzyskamy, gdy SPL sygnału mowy będzie w okolicy 60 dB, co zresztą jest również optymalną wartością w pozostałych przypadkach.
W tej dziedzinie przeprowadzono zresztą sporo badań, z których wynika m.in. iż:
1. Optymalny poziom sygnału mowy jest stały, gdy poziom szumu tła jest mniejszy niż 40 dB(A),
2. W przypadku gdy poziom tła jest większy niż 40 dB(A), optymalny poziom sygnału mowy powinien być utrzymywany na takim poziomie, aby uzyskać stosunek sygnał/szum równy 15 dB(A),
3. Trudności ze zrozumieniem mówcy rosną, gdy poziom sygnału mowy zwiększa się w warunkach, w których S/N jest wystarczająco dobry, by uzyskać perfekcyjną zrozumiałość.
Dodać jeszcze trzeba, iż w celu uzyskania jak najlepszej klarowności nagłaśnianej mowy powinno się „utrzymywać czystość” w paśmie 1-4 kHz. Oznacza to, iż w przypadku prezentacji słownej na podkładzie muzycznym najlepiej jest sygnał muzyczny obrobić korektorem parametrycznym, podcinając o 5, a nawet 10 decybeli ten zakres częstotliwości.
Pogłos
Gdy mówimy o zrozumiałości mowy, pogłos postrzegany jest jako szum, czyli coś niepożądanego. Niewielki pogłos może wpływać korzystnie na ogólne brzmienie mówcy, jednak w momencie gdy spółgłoski zaczną się zamazywać, zrozumiałość zaczyna spadać.
Na pole dźwiękowe wokół mówcy wpływ mają nie tylko fizyczne właściwości kanału głosowego człowieka, ale również jego ciało, a w szczególności głowa.
Kierunkowość
Na rysunku 5 pokazane są charakterystyki kierunkowe statystycznego mówcy, jako źródła dźwięku, zarówno w płaszczyźnie horyzontalnej, jak i wertykalnej.
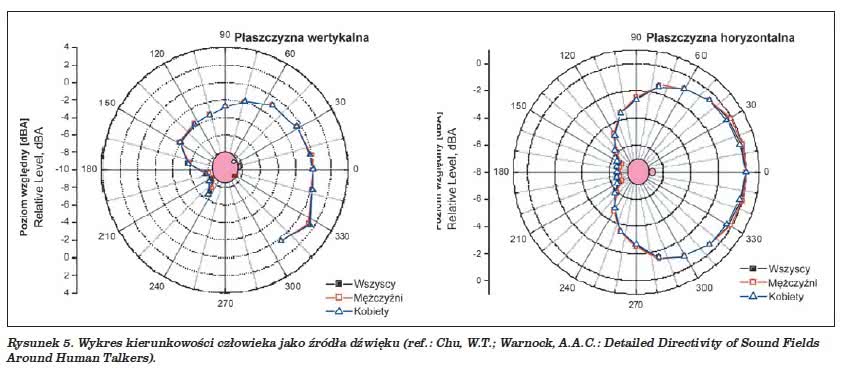
Na wykresie zobrazowano również uśrednione przebiegi osobno dla mężczyzn i kobiet, przy czym, jak widać, różnice są bardzo niewielkie. Pomiary dokonywano w pozycji siedzącej, w odległości 1 m od ust. Jak widać, różnica między poziomami z przodu i z tyłu mówcy wynosi około 7 dB. Jednakże wykresy te nie mówią nam nic o tym, jak to wygląda w funkcji częstotliwości, dla których większe tłumienie występuje przy sopranach niż przy basach.

Pokazuje to kolejny rysunek, numer 6, gdzie dla 18 częstotliwości z zakresu 180-8.000 Hz wykreślono znów charakterystykę kierunkową. Można tu zauważyć, iż kierunkowość w niewielkim stopniu zmienia się do częstotliwości 1 kHz, zaś powyżej niej dość istotnie się zwiększa. Łącząc ten fakt ze znaną nam już informacją, iż częstotliwości powyżej 1 kHz i poniżej 4 kHz odgrywają znaczącą rolę w zrozumieniu mowy, staje się oczywiste, dlaczego tak duże znaczenie w tym przypadku ma właściwe ustawienie mikrofonu, możliwie jak najbliżej osi ust, z przodu przemawiającego.
Wracając jeszcze na chwilę do ogólnych wykresów kierunkowych – obserwując pierwszy z nich, wykreślony w płaszczyźnie wertykalnej, zauważamy, iż najwyższy poziom w porównaniu do innych kierunków uzyskujemy pod kątem ok. 330 stopni. Dzieje się tak dlatego, iż dźwięk jest odbijany przez klatkę piersiową, co bynajmniej nie oznacza, że pierś to najlepsze miejsce do ustawienia mikrofonu.
Odległość i kierunek
Z racji tego, iż raczej bardzo rzadko umieszcza się mikrofon przed mówcą w odległości aż 1 m, interesujące dla nas będzie to, co dzieje się, gdy przetwornik przesuwamy bliżej źródła, czyli mówcy.

Spójrzmy na diagramy z rysunku 7, prezentujące odchyłkę charakterystyk częstotliwościowych dla 4 odległości od mówcy (80, 40, 20 i 10 cm) w stosunku do pozycji referencyjnej, tj. odległości 1 m. Pomiary wykonano w osi oraz pod kątem 45 stopni w górę i w dół od niej. Linia prosta na tych wykresach oznacza, że nie ma różnic w stosunku do charakterystyki referencyjnej, a im większe „góry i doliny”, tym bardziej różni się ona dla danych częstotliwości od tej mierzonej w odl. 1 m.
Na górnym wykresie, przy pomiarze pod kątem 45 stopni z góry, widać, że różnice są niewielkie. Stąd wniosek, iż usytuowanie mikrofonie na statywie, nieco powyżej ust mówiącego, a nawet lekko ponad głową, zapewnia najbardziej stabilne spektrum, niezależnie od odległości mikrofonu od przemawiającego. Zupełnie odwrotnie jest na wykresie dolnym, reprezentującym przypadek ustawienia mikrofonu pod kątem 45 stopni z dołu. Tutaj różnice potrafią być bardzo istotne, a biorą się one z niebagatelnego wpływu odbić dźwięku przez ciało ludzkie. Różnice te są tym większe, im mniej ubioru ma na sobie dana osoba – atrakcyjna pani z dużym dekoltem to widok bez wątpienia pożądany przez większość panów, ale u realizatora dźwięku może wzbudzać uczucia ambiwalentne.
Wykres środkowy, reprezentujący pomiar w osi ust, to wypadkowa obu skrajnych wykresów – różnice są zauważalne, ale mniejsze niż przy ustawieniu przetwornika poniżej linii ust.
Pierś, czoło, policzek
W broadcastingu, szczególnie w TV, często spotykanym sposobem na „zbieranie” głosu danej osoby jest przypięty do ubrania tzw. mikrofon krawatowy. Coraz częściej spotyka się też, nieobce również w aplikacjach live (szczególnie w teatrach czy operach), mikrofony nagłowne (nauszne) lub przylepiane do policzka albo – rzadziej – czoła aktora. Trzeba jednak mieć na uwadze, że takie pozycjonowanie przetworników – pod „dziwnymi” kątami i na stosunkowo małym dystansie – powoduje istotne różnice w spektrum sygnału mowy/wokalu w stosunku do neutralnie i naturalnie brzmiącej pozycji normalnego słuchania, tj. przed mówcą, w odległości kilkudziesięciu centymetrów (spróbujcie przystawić ucho tuż koło policzka albo klatki piersiowej mówiącej osoby, a nausznie stwierdzicie różnice).

Cztery wykresy z rysunku 8 odzwierciedlają te różnice w stosunku do pomiarów w osi ust, w odległości 1 m (wynik uśredniony z pomiarów 10 rożnych osób). Wykres górny reprezentuje przypadek zamontowania mikrofonu krawatowego na wysokości klatki piersiowej, w bezpośredniej odległości od mówcy – jak widać, różnice są bardzo znaczące, szczególnie w zakresie średnicy i wysokiego środka pasma. Kolejny wykres to mikrofon umieszczony na czole – tu jest już dużo lepiej (stąd widać, dlaczego aktorom na scenie często przykleja się miniaturowy przetwornik na czole, choć nie wygląda to tak estetycznie, jak np. na policzku tuż przed uchem), zaś następne pokazują przypadek zamocowania mikrofonu tuż przy uchu oraz na policzku. W każdej z czterech sytuacji można zauważyć dość spore podbicie pasma w okolicy 800 Hz, które trzeba mieć na uwadze i odpowiednio skompensować. Bardziej jednak „groźna” jest degradacja w zakresie średnich częstotliwości, wpływająca na zrozumiałość mowy – zauważalna szczególnie w pozycji przy uchu, a już najbardziej dla mikrofonu krawatowego. Widać też, że mikrofon z boku głowy – koło ucha i na policzku – dość znacząco tłumi najwyższe częstotliwości, co akurat nie zawsze będzie uznawane za dużą wadę takich rozwiązań.
Dodać jeszcze trzeba, czego z wykresów nie możemy odczytać, gdyż są normalizowane do wartości 0 dB, iż poziom sygnału głosu ludzkiego w pozycji „w kąciku uśmiechniętych ust” jest o ok. 10 dB wyższy w stosunku do pozycji na piersi.
Zaopatrzeni w niezbędną wiedzę teoretyczną spróbujmy wykorzystać ją w praktyce, dobierając odpowiednio sposób zainstalowania mikrofonu dla mówcy/ wokalisty.
Wokalowy mikrofon do ręki
1. Wokalowy mikrofon doręczny powinien być usytuowany naprzeciw ust, pod kątem nie większym niż ±30 stopni.
2. Jeśli używany jest mikrofon kierunkowy (kardioidalny, super- lub hiperkardioidalny albo typu shotgun), powinien on być skierowany zgodnie z osią ust, przy czym oś ta przebiega poziomo (a nie typu „lód włoski”).
3. Zbyt gęsta gąbka chroniąca np. od wiatru może redukować wysokie częstotliwości – należy mieć to na uwadze i odpowiednio skompensować.
Mikrofon krawatowy/lavalier
Spektrum mowy w pozycji przypisanej mikrofonom krawatowym wykazuje istotny ubytek w zakresie odpowiedzialnym za zrozumiałość mowy, tj. 3-4 kHz. Jeśli pracujemy z mikrofonem o płaskiej charakterystyce przenoszenia, przyczepionym na piersi danej osoby, należy obligatoryjnie skompensować ten efekt, podbijając zakres 3-4 kHz o 5-10 dB. Często jednak mikrofony typu lavalier mają to uwzględnione w swojej charakterystyce przenoszenia, dlatego też nie brzmią zbyt „pięknie” (zbyt „ostro”), jeśli mówimy do nich bezpośrednio, trzymając w okolicy ust.
Mikrofon nagłowny/headset
Jak już wspomnieliśmy, spektrum mikrofonów umieszczonych na głowie jest bardziej wyrównane niż w przypadku przetworników zainstalowanych w okolicy klatki piersiowej, charakteryzuje się też ok. 10 dB wyższym poziomem niż „krawatowiec” (przy takich samych czułościach przetworników). Występuje jednak dość istotny ubytek najwyższych częstotliwości, który trzeba skompensować korekcją. Najmniej tego niepożądanego efektu będziemy mieli, jeśli przyczepimy mikrofon na czole, na linii włosów – choć wygląda to „tak sobie”, zapewnia największą naturalność brzmienia, jeśli chodzi o mikrofony nagłowne.
Mikrofon pulpitowy
1. Mikrofony pulpitowe używane są przeważnie przy różnych odległościach od źródła (czyli ust), powinny więc być to przetworniki kierunkowe, szczególnie w zakresie częstotliwości powyżej 1 kHz.
2. Mikrofon musi być skierowany na usta przemawiającego.
3. Mikrofon montowany bezpośrednio do mównicy/ambony/podium powinien charakteryzować się dużą odpornością na wibracje, nie przenosić stuków i innych zakłóceń pochodzących od pulpitu/ mównicy.
Mikrofon na statywie
W przypadku mikrofonu umieszczonego na statywie najbardziej wyrównane i niezależne od odległości spektrum mowy uzyskamy ustawiając mówcę przed mikrofonem, nieco poniżej niego (mikrofon powyżej głowy). W takim jednak przypadku nie obejdzie się raczej bez przetwornika typu shotgun, zwłaszcza gdy obok są inne źródła dźwięku/hałasu.
Hałaśliwe lub pogłosowe otoczenie
W takich sytuacjach trzeba umieszczać mikrofon jak najbliżej ust mówiącego – mikrofon nagłowny lub nauszny będzie tu chyba najlepszym rozwiązaniem, zwłaszcza jeśli osoba nie jest wprawna w posługiwaniu się mikrofonem do ręki i/lub nie potrafi zachować małej odległości od przetwornika na statywie/pulpitowego. Najlepiej jeśli przetwornik mikrofonu będzie miał charakterystykę kierunkową – kardioidalną lub hiperkardioidalną.
Piotr Sadłoń


