









X4L - wzmacniacz z DSP z serii X
Biznes „nagłośnieniowy” – w porównaniu z innymi dziedzinami techniki (np. przemysłem samochodowym, czy ...

Technika cyfrowa otwiera przed nami zupełnie nowe możliwości i sposoby obróbki, nieosiągalne dla sygnałów analogowych. Dzięki nim możemy dokonywać wielu operacji na sygnale, które w domenie analogowej były niemożliwe lub bardzo trudne do wykonania.
O kilku takich operacjach, coraz częściej stosowanych w przetwarzaniu sygnałów cyfrowych, i ich wykorzystywaniu przy pracy z sygnałami audio postaram się przystępnie w tym artykule opowiedzieć. Zacznijmy od
Predykcja liniowa jest metodą umożliwiającą obliczanie estymaty wartości próbki dzięki znajomości próbek ją poprzedzających. Cóż to jest ta estymata? Estymata (pojęcie znane wszystkim tym, którzy zajmują się statystyką) to inaczej oszacowanie pewnej nieznanej wartości jakiegoś parametru lub wielkości. Metodą tą można więc obliczyć (oszacować) wartość nieznanych próbek. Algorytmy predykcyjne mają charakter iteracyjny (czyli wykonywane są w pętli krok po kroku, aż do momentu zakończenia „pętli”, czyli iteracji), przy czym w każdym kroku obliczana jest estymata wartości pojedynczej, kolejnej próbki.
Rząd predykcji określa z ilu wcześniejszych próbek będziemy obliczać wartość próbki przewidywanej. Oczywiste jest, że im więcej tych próbek, tym wynik szacowania będzie obarczony mniejszym błędem. Automatycznie jednak zwiększa się ilość wykonywanych operacji matematycznych, a to wymaga większych mocy obliczeniowych lub/i wydłuża czas operacji. Po obliczeniu estymaty próbki jest ona porównywana z wartością rzeczywistą próbki pobranej z sygnału. Na skutek tego można podjąć decyzję o zastąpieniu tej próbki właśnie próbką wyliczoną dzięki predykcji liniowej.
Pytanie, w jakim celu zastępować próbkę z sygnału próbką obliczoną? Ano w normalnej sytuacji, gdy wszystko „działa, jak należy” faktycznie zabieg ten mijałby się z celem, choćby z tego powodu, iż jaki byśmy nie przyjęli wielki rząd predykcji i przez to dokładność obliczeń, zawsze obliczona wartość próbki będzie obarczona pewnym błędem. Są jednak takie przypadki, że nawet taki błąd będzie nieistotny w porównaniu z tym, co może się „podziać” w sygnale. Ot choćby dla przykładu: kiedy na sygnał użyteczny nałoży nam się jakiś tzw. klik albo inny „śmieć”, albo gdy próbka ulegnie przekłamaniu lub po prostu zaniknie w procesie przesyłania bądź zapisu na nośnik. Nieco więcej na ten temat za moment.
Teraz jeszcze chciałbym wrócić do samego procesu predykcji. Istnieje bowiem taka opcja, że w przypadku niemożliwości poprawnego odebrania kolejnej próbki możliwe jest kontynuowanie estymowania (szacowania) próbek z użyciem próbek wcześniej estymowanych na podstawie predykcji. Oczywiście, należy się liczyć z tym, że w takim przypadku błąd estymacji kolejnej próbki może narastać.
Jednym z powszechnych zastosowań predykcji liniowej, o którym warto wspomnieć słów kilka, jest estymacja transmitancji toru transmisyjnego na podstawie próbek sygnału odbieranego na wyjściu tego toru. Każdy kanał transmisyjny charakteryzuje się pewną funkcją opisującą właściwości tego toru czy kanału, zwaną transmitancją. Jeśli znamy tę transmitancję, możemy np. przewidzieć, w jaki sposób sygnał podawany na wejście takiego toru ulegnie zmianie na wyjściu, a więc jest to ważna wiedza. Nie będziemy zagłębiać się we „wzorologię” i opis zer, biegunów itp. Zainteresowanych bardziej szczegółowo tą tematyką odsyłam do fachowej literatury. Dla nas istotne jest to, że dzięki takim zabiegom, czyli umiejętności wyznaczania transmitancji toru tylko na podstawie znajomości odbieranego sygnału, kiedy nie znamy dokładnie sygnału pobudzającego (czyli, inaczej mówiąc, nadawanego z drugiej strony „kabla”), dysponujemy mocnym narzędziem. Narzędzie to znajduje zastosowanie np. w modelowaniu akustycznego traktu głosowego, które z kolei jest wykorzystywane w syntezie mowy, ale i również w procesie jej rozpoznawania. I jeszcze jedno bardzo przydatne zastosowanie: tory i kanały transmisyjne często wprowadzają różne zniekształcenia sygnału, zupełnie przez nas niepożądane. Skoro potrafimy oszacować transmitancję toru, czyli de facto jego wpływ na sygnał oryginalny, to dzięki tej wiedzy będziemy również mogli zredukować jego wpływ na tenże sygnał. Dotyczy to także zniekształceń wprowadzanych w procesie rejestracji sygnału, gdyż proces ten również możemy potraktować jako szczególny przypadek przesyłania sygnału poprzez tor o pewnej transmitancji. Jak tego dokonać?
Jeśli znamy transmitancję toru wyznaczoną na podstawie predykcji (a zakładamy, że znamy), to możemy na jej podstawie utworzyć filtr odwrotny (inwersyjny), który pozwoli usunąć wpływ niepożądanej transmitancji z odbieranego sygnału. Operacja taka nosi nazwę wybielania w dziedzinie częstotliwości widma.
Inne zastosowanie predykcji liniowej polega na wykorzystaniu jej do wykrywania zakłóceń w sygnale fonicznym. W wykonaniu najprostszym metoda ta jest co prawda mało skuteczna – sygnał muzyczny zawiera wiele pożądanych dźwięków impulsowych (perkusyjnych, transjentów), których wystąpienie będzie traktowane na równi z pasożytniczymi impulsami. Jednak poprawiając algorytm osiągnięto bardziej zadowalające rezultaty. Poważną wadą jest otrzymywanie niepoprawnych współczynników predykcji w przypadku zaklasyfikowania próbki zniekształconej jako poprawnej. Sytuacja taka powoduje propagację błędu, który przenosi się na następne próbki. Z tej przyczyny metoda ta jest mało skuteczna w obecności szumu. Radą na to jest
Nie jest to skrót najnowszej samonaprowadzającej się rakiety typu powietrze- ziemia. Jest to tzw. model ARMA, a sam skrót pochodzi od angielskich słów Autoregressive Moving Average. Wykorzystując model autoregresywny można rekonstruować sygnał foniczny, obarczony szumem i zakłóceniami, metodą interpolacji adaptacyjnej. Nie zagłębiając się w szczegóły matematyczne (nadmienię tylko, że obliczenia są bardzo skomplikowane ze względu na obliczenia macierzowe wstępujące w algorytmie) okazuje się, że wyniki interpolacji otrzymane przy zastosowaniu modelu ARMA są bardzo dobre w przypadku sygnałów o dużym stosunku sygnał/szum. Dla sygnałów o stosunku sygnał/szum poniżej 20 dB próbki interpolowane są z zauważalnym, a w zasadzie należałoby powiedzieć słyszalnym, błędem.
Filtracja to w ogólnym przypadku operacja tak popularna w dziedzinie sygnałów audio, jak dodawanie przypraw w gotowaniu (o czym zresztą pisaliśmy przy okazji omawiania filtrów FIR i IIR). Znana jest od bardzo dawna i od dawien dawna wykorzystywana – realizowana wcześniej w dziedzinie analogowej, obecnie coraz chętniej w domenie cyfrowej. Filtracja w klasycznym tego słowa rozumieniu polega na przepuszczeniu sygnału przez filtr, który pewną część pasma przepuści, a pewnej nie, czyli inaczej część pasma „wytnie”. Ten rodzaj filtracji będziemy stosować, jeśli chcemy pozbyć się jakieś konkretnej części pasma (filtry pasmowo- przepustowe i pasmowo-zaporowe), zmienić barwę dźwięku lub ograniczyć pasmo od dołu czy od góry (filtry górno i dolnoprzepustowe). Do odszumiania sygnału filtry takie natomiast nie nadają się zbytnio, gdyż wtedy należałoby założyć, że sygnał użyteczny jest przenoszony w określonym paśmie częstotliwości, a szum jest związany z inną częścią pasma, i pasma te na siebie nie zachodzą. Tak niestety nie jest. Przeważnie, mając do czynienia z sygnałem zaszumionym, spotykamy się z sytuacją, gdy sygnał użyteczny i szum leżą w tym samym paśmie, a więc są ze sobą splecione. Sygnał taki można więc przedstawić jako sumę szumu i sygnału użytecznego.
Probabilistyczne ujęcie filtracji wykorzystuje natomiast fakt, że sygnał użyteczny i szum charakteryzują się określonymi właściwościami statystycznymi. Zadanie filtracji w ujęciu statystycznym polega na możliwie dokładnym odjęciu szumu od sygnału użytecznego, za pomocą obróbki w filtrze, który musi adaptować swoją charakterystykę w zależności od bieżących zmian sygnału i szumu oraz ich wzajemnych relacji. Na tym ogólnie polega filtracja adaptacyjna, teraz może kilka szczegółów.

Zasada działania filtru adaptacyjnego polega na usuwaniu korelacji (czyli, mówiąc w uproszeniu, zależności) pomiędzy sygnałami e(n) i y(n). Jeśli sygnały x(n) i y(n) są w jakiś sposób skorelowane (czyli, inaczej mówiąc, składnik szumu zawartego w x(n) jest skorelowany z sygnałem y(n)), wtedy filtr będzie dokonywał samoczynnej adaptacji swoich wag (parametrów), dopóki taka korelacja nie zostanie usunięta z wyjścia e(n). Dzieje się tak dlatego, że filtr adaptacyjny „produkuje” możliwie najlepszą replikę składnika szumu w sygnale x(n), która następnie jest usuwana z x(n). Sygnał wyjściowy e(n) będzie zawierał więc głównie pożądany, niezaszumiony sygnał. Trochę to wszystko brzmi skomplikowanie. Chodzi głównie właśnie o to, aby sygnał wyjściowy nie był skorelowany z sygnałem wejściowym (zaszumionym).
Istotnym wymogiem algorytmu filtracji adaptacyjnej jest to, aby statystyczne właściwości sygnału wejściowego nie zmieniały się zbyt szybko, po to, by filtr miał czas na dostrojenie swoich parametrów do wartości optymalnych. Jeśli statystyczne właściwości sygnału wejściowego zmieniają się dostatecznie wolno, wtedy filtr nadąża za takimi zmianami poprzez dopasowanie (adaptację) swoich parametrów do nowych, optymalnych wartości.
Inny pomysł jest oparty na metodzie operującej na widmie sygnału.
Wspomniałem już wcześniej o dwóch metodach, dzięki którym można w pewnym stopniu usuwać szum z materiałów dźwiękowych: z wykorzystaniem modelu ARMA i, nieco szerzej opisany powyżej, sposób z wykorzystaniem statystycznych właściwości sygnału, oparty o filtrację adaptacyjną. Jednakże najpopularniejszą obecnie, i w praktyce często wykorzystywaną, jest redukcja szumu w oparciu o tzw. odejmowanie widmowe. Polega ona na określeniu średniego widma sygnału i średniego widma szumu we fragmentach nagrania i dokonaniu odejmowania obu reprezentacji widmowych. W ten sposób uzyskuje się efekt poprawy średniego stosunku sygnału do szumu dla całego nagrania. Aby uzyskać uśrednione w czasie widmo szumu musimy dysponować fragmentem nagrania zawierającym sam szum, bez sygnału „użytecznego”. Zaznaczamy więc fragment zawierający kilkusekundową przerwę w nagraniu (standardowo na początku lub pomiędzy utworami bądź frazami), z którego następnie obliczane jest widmo średnie szumu. Następnie widmo to jest odejmowane od widma całego sygnału, ze współczynnikiem zależnym od nastawienia przez „operatora”, dzięki któremu określamy stopień redukcji szumu (zasadniczo jest to parametr w programie lub pluginie określany w dB). Odejmowanie widmowe można przeprowadzić w sposób bardziej precyzyjny, jeżeli wprowadzi się uzależnienie stopnia ingerencji w zaszumiony sygnał od częstotliwości. Inną innowacją jest zastosowanie nieliniowej estymacji widma szumu.
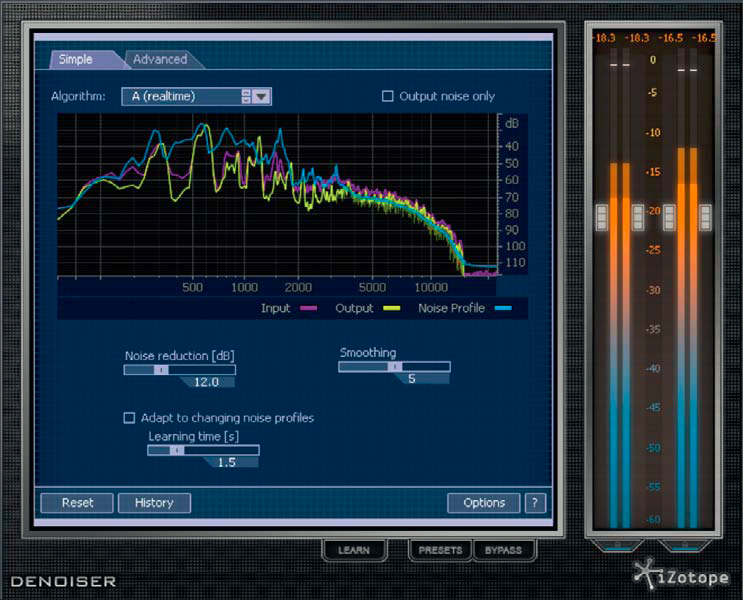
Najpopularniejszą obecnie, i w praktyce często wykorzystywaną, jest redukcja szumu
w oparciu o tzw. odejmowanie widmowe – przeważnie w formie plug-inów.
Najnowsze badania, mające na celu poprawę redukcji szumu i jednocześnie zmniejszenie niekorzystnego działania algorytmów odszumiających na sygnał użyteczny, są ukierunkowane na zastosowanie w tych celach inteligentnych algorytmów uczących się, opartych na sieciach neuronowych.

Dla przykładu, na rysunku powyżej podano schemat takiego algorytmu. Idea jego działania jest podobna, jak opisywanego nieco wcześniej, i oparta o odejmowanie widmowe, z tą różnicą, że w tym przypadku sterowane przez algorytm uczący się. Podobnie jak w klasycznym de-noiserze pobierany i analizowany jest fragment samego szumu, z tym że w tym przypadku analiza przebiega w poszczególnych pasmach odpowiadających pasmom krytycznym słuchu. W podobny sposób przetwarzany jest sygnał zaszumiony, tzn. wyznaczane są rozkłady widmowej gęstości mocy sygnału zaszumionego również w poszczególnych podpasmach. Następnie rozkłady widmowej gęstości mocy szumu ρ i sygnału σ są porównywane w module wnioskowania, pełniącym rolę inteligentnego komparatora. Jego zadaniem jest wykrywanie powiązań (korelacji) pomiędzy tymi dwoma rozkładami, czyli określanie miary podobieństwa pomiędzy nimi. Następnie sygnał jest filtrowany z uwzględnieniem rozkładu p(ρ,σ). W rezultacie na wyjściu układu pojawia się pożądany sygnał x~, będący estymatą sygnału niezaszumionego x. To oczywiście ogólna idea działania takiego algorytmu uczącego się, ale szczegółowy opis wymagałby zagłębiania się w tematykę sieci neuronowych, a nie czas i miejsce na to w tym artykule. Poprzestańmy więc na tym.

Denoiser może również występować w wersji sprzętowej, tak jak ten nieprodukowany już SNR2000 Behringera.
Metody usuwania trzasków można podzielić na dwie grupy. Pierwsze polegają na wygładzaniu sygnału (np. filtracja dolnoprzepustowa i filtracja medianowa). Niekorzystną cechą ich jest ingerencja w cały rekonstruowany sygnał, przez co powstają słyszalne zniekształcenia, zwane szumami muzycznymi.
Drugą grupę stanowią metody wykrywania i restaurowania sygnału, przebiegające w dwóch etapach:
1. detekcja – w procesie tym określane są przedziały występowania zakłóceń impulsowych
2. rekonstrukcja – w procesie tym następuje możliwie dokładne odtworzenie wartości próbek sygnału na podstawie przebiegu sygnału niezniekształconego, sąsiadującego z przedziałami zakwalifikowanymi do rekonstrukcji.
Lokalizacja zniekształceń impulsowych polega na analizie sygnału w celu wykrycia próbek o wartościach zniekształconych przez trzask. Wynikiem procesu lokalizacji trzasków jest oznaczenie granic przedziałów zawierających uszkodzone próbki.
Jedna z podstawowych metod wykrywania trzasków opiera się na analizie obwiedni amplitudy widma sygnału, otrzymanego przy użyciu transformacji Fouriera. Podarujemy sobie szczegółowy opis algorytmu, istotne jest natomiast to, że metoda ta jest skuteczna przede wszystkim w odniesieniu do krótkich trzasków o dużej amplitudzie. Ponadto niektóre transjenty i dźwięki perkusyjne algorytm rozpoznaje jako trzaski i mogą być usunięte, zupełnie niepotrzebnie. Pewną poprawę jakości działania algorytmu można natomiast uzyskać poprzez zastosowanie transformacji falkowej zamiast transformacji Fouriera.
Druga faza usuwania trzasków to proces rekonstrukcji uszkodzonych próbek. Część metod rekonstruowania zniekształconych przedziałów wykorzystuje jednocześnie informację o sygnale dostępną przed oraz za uszkodzonym fragmentem. Metody te należą do grupy metod interpolacji. Pozostałe metody prezentują na ogół podejście polegające na obliczaniu dwóch estymat sygnału: lewostronnej, na podstawie wartości próbek sprzed uszkodzonego przedziału, oraz prawostronnej, opartej na analizie próbek za tym przedziałem. Tego typu podejście jest ekstrapolacją.
Dalszą poprawę zarówno detekcji, jak i rekonstrukcji zniekształceń impulsowych (trzasków) można uzyskać wkraczając w technikę sieci neuronowych i algorytmów uczących się, co też obecnie ma miejsce, choć, o ile mi wiadomo, na razie jest w fazie badań. Być może już niedługo będziemy mieli do czynienia z sieciami neuronowymi i opartymi o ich działanie urządzeniami redukującymi szumy i trzaski, póki jednak co jest to domena panów w białych fartuchach i wcale nie mam tu na myśli psychiatrów.
Obecnie za pomocą wtyczek typu de-noiser, de-clicker i de-buzzer można usunąć z nagrań
większość niepożądanych dźwięków, bez znaczącej szkody dla nagranego materiału
Na koniec kilka zdań o bardzo ciekawej technice wykorzystywanej w przetwarzaniu cyfrowym, które znajduje również zastosowanie w przetwarzaniu cyfrowego audio.
zwana też metodą ślepego rozplotu. Metoda ślepego rozplotu polega na usuwaniu wpływu nieokreślonego filtru na nieznany sygnał poprzez obserwację sygnału dostępnego na wyjściu tego filtru. Ślepy rozplot znajduje zatem zastosowanie wtedy, gdy występuje potrzeba rozdzielenia dwóch sygnałów, lecz nie jest znana charakterystyka żadnego z nich. Ot, dla przykładu: renowacja starych nagrań – mamy nagranie zrealizowane x lat temu i nagrane na starą trzeszczącą płytę. Możemy oczywiście zastosować de-clicker, aby usunąć trzaski płyty, odszumić je i już będzie lepiej. Ale możemy, przynajmniej teoretycznie, uniezależnić się od ułomności systemu nagrywającego, który lat temu x był bez wątpienia niespecjalny (wąskie pasmo, zakłócenia itd. itd.).
Technika rozplotu jest oparta na założeniu, że sygnał odczytywany z nośnika jest splotem. W wyniku zwykłej, liniowej filtracji będzie można „wyłączyć” człon reprezentujący niepożądaną transformację H(f). Właśnie dzięki „wyizolowaniu” z sygnału transmitancji H(f) można na jej podstawie zaprojektować filtr odwrotny, który może być zastosowany do usuwania zniekształceń barwy dźwięku powstałych w trakcie nagrania.
Tak wygląda teoria, w praktyce trzeba poczynić wiele założeń upraszczających, które powodują, że to wszystko nie jest takie łatwe, jakby wynikało z teorii. Fakt jest jednak faktem, że sama idea jest słuszna i już przynosi pewne pozytywne efekty. A co będzie za lat kilka....? To się dopiero okaże.
Jan Erhard
Jan Erhard z wykształcenia jest informatykiem i specjalistą od sieci cyfrowych, zaś z zamiłowania muzykiem. Zajmuje się też realizacją dźwięku, stąd jego zainteresowania i duża wiedza na temat cyfrowego przetwarzania sygnałów.


